Features
We have the most advanced solution for extracting tables from images
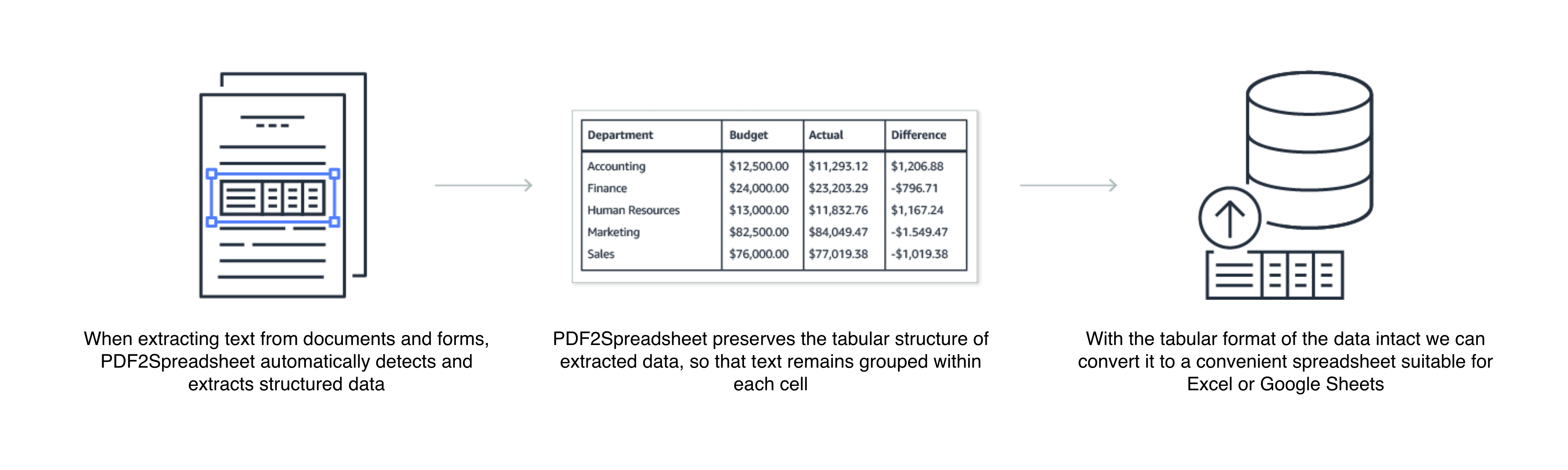
Robust table extraction technology
We use artificial intelligence to "read" documents as a person would, to extract printed text and handwriting without configuration, training, or custom code.
PDF2Spreadsheet automatically detects a document’s layout and the key elements on the page, understands the data relationships in any embedded tables, and extracts everything with its context intact.
Tools you already use
We integrate with Microsoft Excel, Google Sheets, Comma-Separated Values or JSON files.
Load files from your computer, phone or import them on the web. Upload PDFs from your Box, Dropbox, Google drive or Microsoft OneDrive folder.
International
We support many languages: English, Spanish, German, Italian, Portuguese, and French. PDF2Spreadsheet will automatically detect and extract the information.
Start On Demand
No upfront cost nor setup required. Start extracting tables from PDF today.
Enterprise-ready
Start with no upfront cost with our on-demand plan. We can scale at any transaction volume you need.
Share files with your colleguages by inviting them to your team.
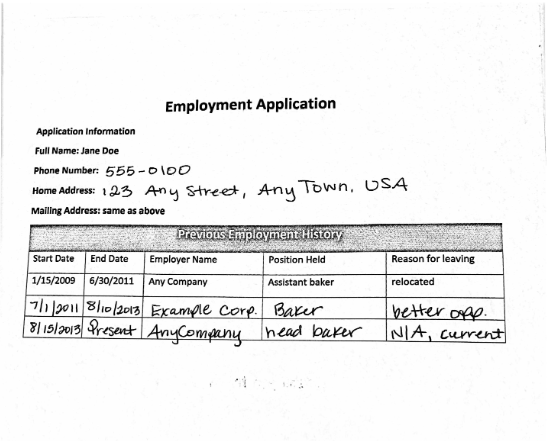
OCR a handwritten table from a scanned document
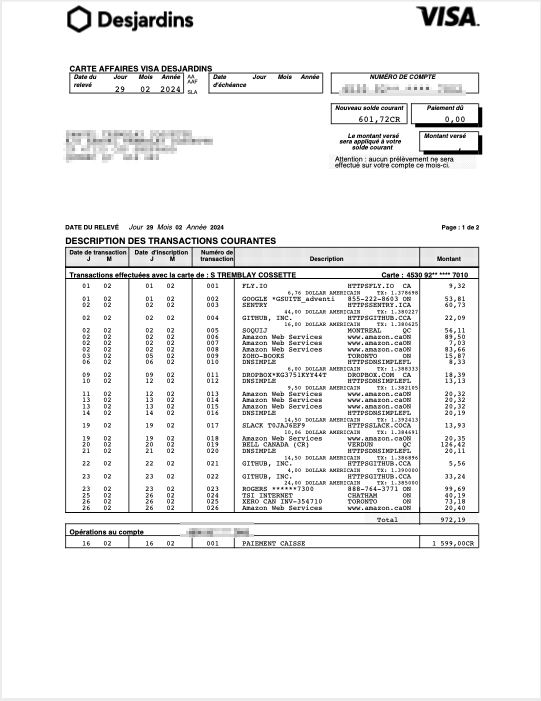
Convert a bank statement to Excel
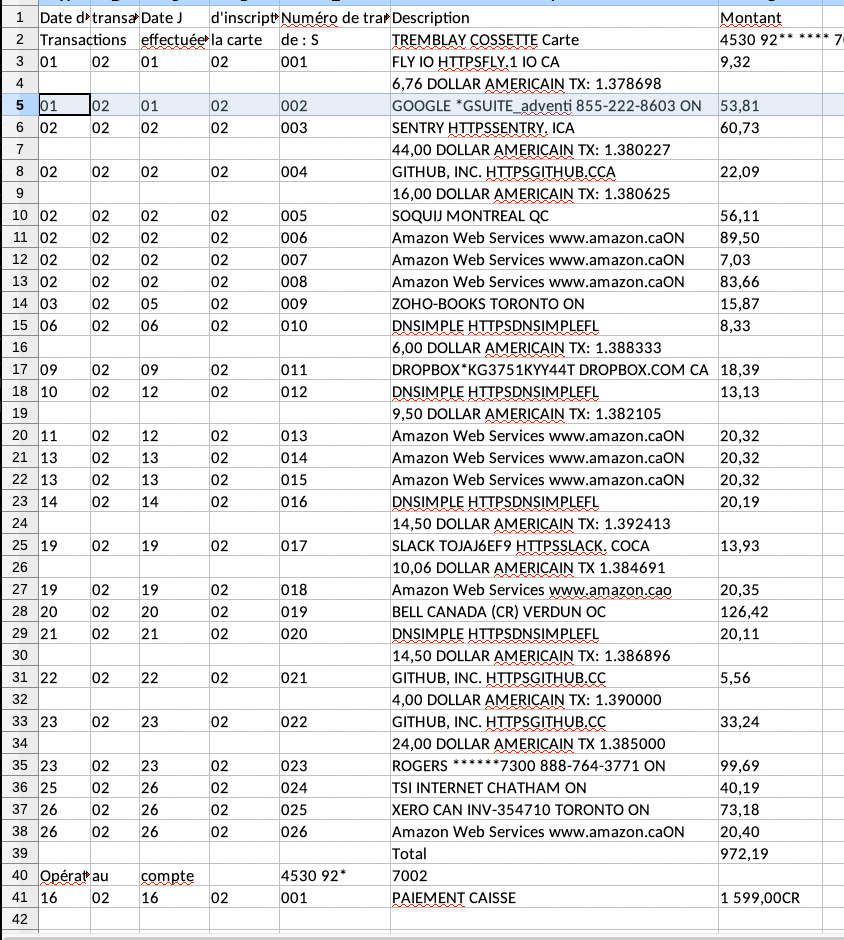
Import a grid from an image
Parse a product Catalog to CSV
Convert a utility statement to Excel

Simple Pricing
Start free. Upgrade whenever you want.